Preparing Your Website for the Future of AI Search With llms.txt

In the past decade, SEO best practices have focused on traditional search engines such as Google, Bing, Yahoo, and others. But times are changing. Rapid advances in AI systems like ChatGPT, Claude, or Perplexity are reshaping how users search for information online.
Instead of typing keywords into a search bar, more people are now asking questions in natural language and receiving curated answers compiled by language models. This shift isn't just a trend, it´s becoming the next evolution of digital search.
If your content isn’t being indexed by AI systems, it risks becoming invisible to a growing share of users. To make sure your content is accessible and properly presented in AI-generated responses, there's an emerging standard you need to know about: llms.txt.
What Is llms.txt and Why Does It Matter?
Think of llms.txt as LLM instructions about your website content. Despite the name similarity, llms.txt is not a robots.txt replacement or extension.
While robots.txt helps traditional search engines understand which pages they can and can't crawl, llms.txt provides large language models (LLMs) with a clear, AI-friendly index of your website content.
It acts as a content map, similar to sitemap.xml used by traditional search engines, but specifically designed for AI bots, enabling them to easily find, understand, and use your content.
As AI-driven search becomes more prominent, having a clean, accurate, and structured llms.txt file could be the difference between being included in AI results or left out entirely.
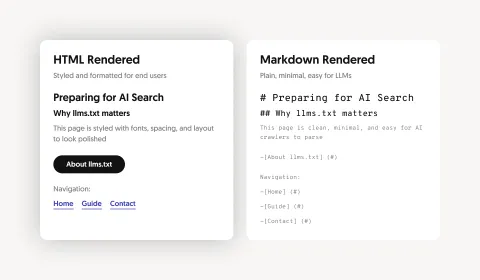
AI Search vs. Traditional Search
LLMs can process large amounts of content, but cluttered websites with navigation, scripts, or ads can reduce relevance and increase hallucinations. Providing stripped-down Markdown versions via a llms.txt file gives AI crawlers clean, structured content, improving accuracy, preserving context, and making it easier to index and use your information.
Traditional Search
- Relies heavily on keywords and ranking factors
- Returns lists of ranked pages
- Requires users to click through results
- Reliance on sitemap.xml and robots.txt
- Process HTML content
AI Search
- Focuses on understanding context and intent
- Delivers curated, highly relevant answers
- Provides summarised, synthesised information
- Reliance on llms.txt and clean Markdown files
- Process Markdown format
Key Benefits of Using llms.txt
- Control: decide exactly which content AI tools can access, index, and present.
- Clarity: guide AI bots to high-value content that’s easy for them to parse.
- Visibility: increase your chances of appearing in AI-generated answers.
- Competitive advantage: adopt llms.txt early to stay ahead of evolving AI search technologies.

llms.txt Format and Implementation Best Practices
- Create a root-level /llms.txt Markdown format, including headers, summaries, and structured links (e.g., https://example.com/llms.txt).
- Select high-value content pages that best represent your website.
- Convert these pages to Markdown (.md): lightweight and optimised for AI crawling.
- Include references to the original HTML on each .md page for context.
- Organise your llms.txt using Markdown lists with descriptive titles and brief summaries:
- # Project title
- > A short description of your project
- ## Section name
- - [Page title](https://example.com/page.md): brief preview or description
This format helps LLMs quickly identify, understand, and retrieve your most valuable content.
Common Pitfalls When Optimising for LLMs
If you're creating Markdown versions of your content for large language models (LLMs), make sure those files don’t show up in traditional search results. You don’t want someone searching for your company name on Google to land on a raw .md version of your homepage.
There are a few ways to prevent this:
Block Access to .MD Files in robots.txt
You can tell traditional search engines not to access Markdown files using your robots.txt file:
User-agent: *
Disallow: /*.md$
or, more specifically:
User-agent: Googlebot
Disallow: /*.md$
User-agent: Bingbot
Disallow: /*.md$
Disallowing .md files in your robots.txt will stop traditional search engines from crawling that content. LLM crawlers do not follow or respect robots.txt, so .md files will still be accessible to them (this is our actual goal). Remember, this method is not fully reliable to prevent page indexing, it only restricts crawling of those pages.
Use Noindex Headers or Block Crawlers Entirely
You can add HTTP response headers to tell traditional search engines not to index specific pages:
X-Robots-Tag: noindex
This can be applied selectively based on the user-agent, so only traditional search engines receive the noindex directive while LLM crawlers remain unaffected. To do this, you’ll need access to your web server or a CDN that supports conditional headers.
Alternatively, you can block traditional search engines entirely from accessing Markdown files. This goes a step further than noindex by preventing them from even loading the page. Again, this can be done at the server or CDN level by checking the user-agent and denying access.

How We Set Up Our Website for LLM Crawlers
If you're using Drupal, setup is straightforward thanks to two helpful modules:
- llms_txt: automatically generates the llms.txt file for your website.
- markdownify: converts HTML content into clean Markdown for easier parsing.
Once installed, these modules allow you to select which content should be included in your llms.txt, convert it to Markdown, and publish it in a structured format LLMs can easily interpret.
To keep these Markdown files out of traditional search engines, we did the following:
- Configured robots.txt to block traditional search engines from crawling .md files.
- Set up our CDN to completely block access to .md files for traditional search engines.
Why Start Implementing llms.txt Now?
AI indexing standards are evolving, and early adopters are gaining a competitive edge. As of now, major AI companies like OpenAI, Anthropic, Perplexity, and others have begun consulting llms.txt files when crawling websites (“The value of llms.txt: Hype or real?”). It means that by implementing llms.txt today, you’re preparing your site for the future of AI search.
How Can We Help?
We specialise in preparing websites for the new era of AI-driven search, guiding you through every step of the llms.txt implementation process.
Our team helps you select the most valuable content to feature in your llms.txt, install and configure the necessary Drupal modules and convert your website’s content into clean, AI-optimised Markdown.
We also help configure your setup correctly to make sure only LLM crawlers can access markdown content, and provide ongoing support as AI indexing standards continue to evolve.
Ready to make your site AI-search-ready? Let’s get started today and ensure your content becomes part of the AI conversation.
Other Highlights
Webinar Recording: Making Informed Choices About AI for Your Marketing Needs

Thinking about AI for marketing? Discover how to identify high-impact use cases for AI adoption and...
Looking Into the Future of Drupal AI

The future of Drupal is AI-powered. Discover the groundbreaking initiative driving responsible...